Microservices instrumentation
Mon, Nov 18, 2019What makes microservices instrumentation different than instrumentation of monolithic systems?
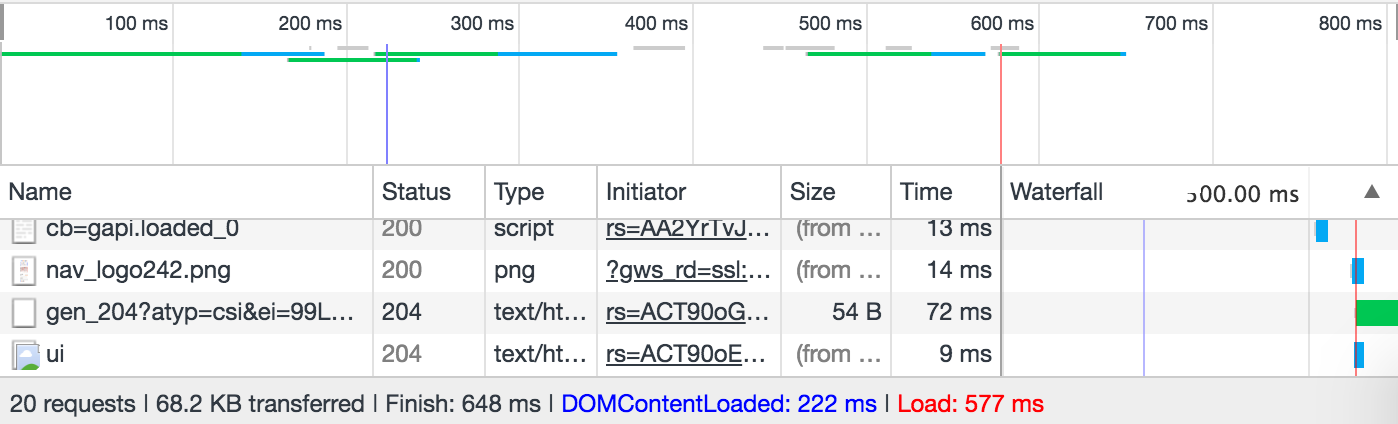
Observability activities involve measuring, collecting, and analyzing various diagnostics signals from a system. These signals may include metrics, traces, logs, events, profiles and more. In monolithic systems, the scope is a single process. A user request comes in and goes out from a service. Diagnostic data is collected in the scope of a single process.
When we first started to build large-scale microservices systems, some practices from the monolithic systems didn’t scale. A typical problem is to collect signals and being able to tell if we are meeting SLOs between them. Unlike the monolithic systems, nothing is owned end-to-end by a single team. Various teams build various parts of the system and agree to meet on an SLO.
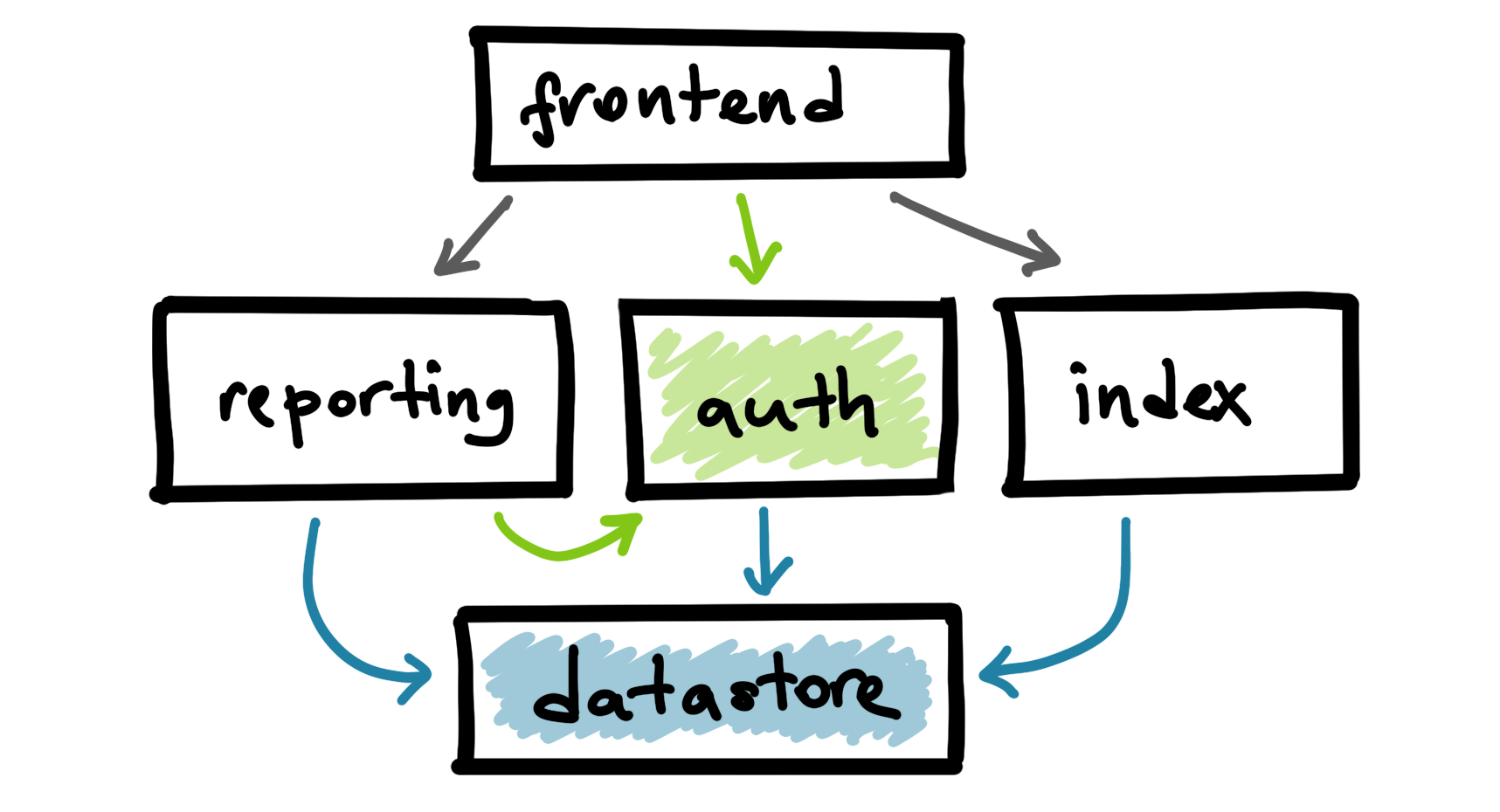
Authentication service depends on the datastore and ask their team to meet a certain SLO. Similarly, reporting and indexing services depend on datastore.
In microservices architectures, it is likely that some services will be a common dependency for a lot of teams. Some examples of these services are authentication and storage that everyone needs and ends up depending on. On the other hand, more particularly, expectations from services vary. Authentication and indexing services might have wildly different requirements from the datastore service. Datastore service needs to understand the individual impact of all of these different services.
This is why adding more dimensions to the collected data became important. We call these dimensions labels or tags. Labels are key/value pairs we attach to the recording signal, some example labels are the RPC name, originator service name, etc. Labels are what you want to breakdown your observability data with. Once we collect the diagnostics signal with enough dimensions, we can create interesting analysis reports and alerts. Some examples:
- Give me the datastore request latency for RPCs originated at the auth service.
- Give me the traces for rpc.method = “datastore.Query”.
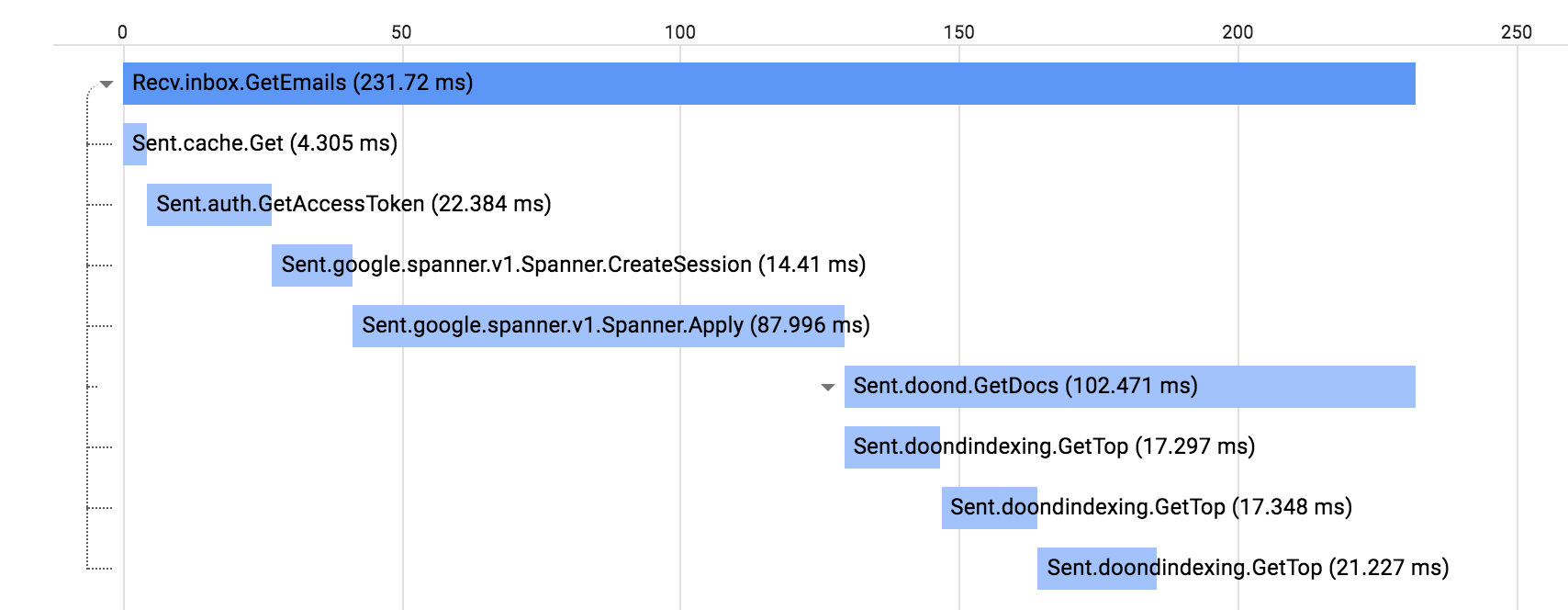
The datastore service is decoupled from the other services and doesn’t know much about the others. So it is not possible for the datastore service to add fine grained labels that can reflect all the dimensions user want to see when they break down the collected diagnostics data.
The solution to this problem is to produce the labels at the upper-level services that calls into the lower-level services. After producing these labels, we will propagate them on the wire as a part of the RPC. The datastore service can enrich the incoming labels with additional information it already knows (such as the incoming RPC name) and record the diagnostics data with the enriched labels.
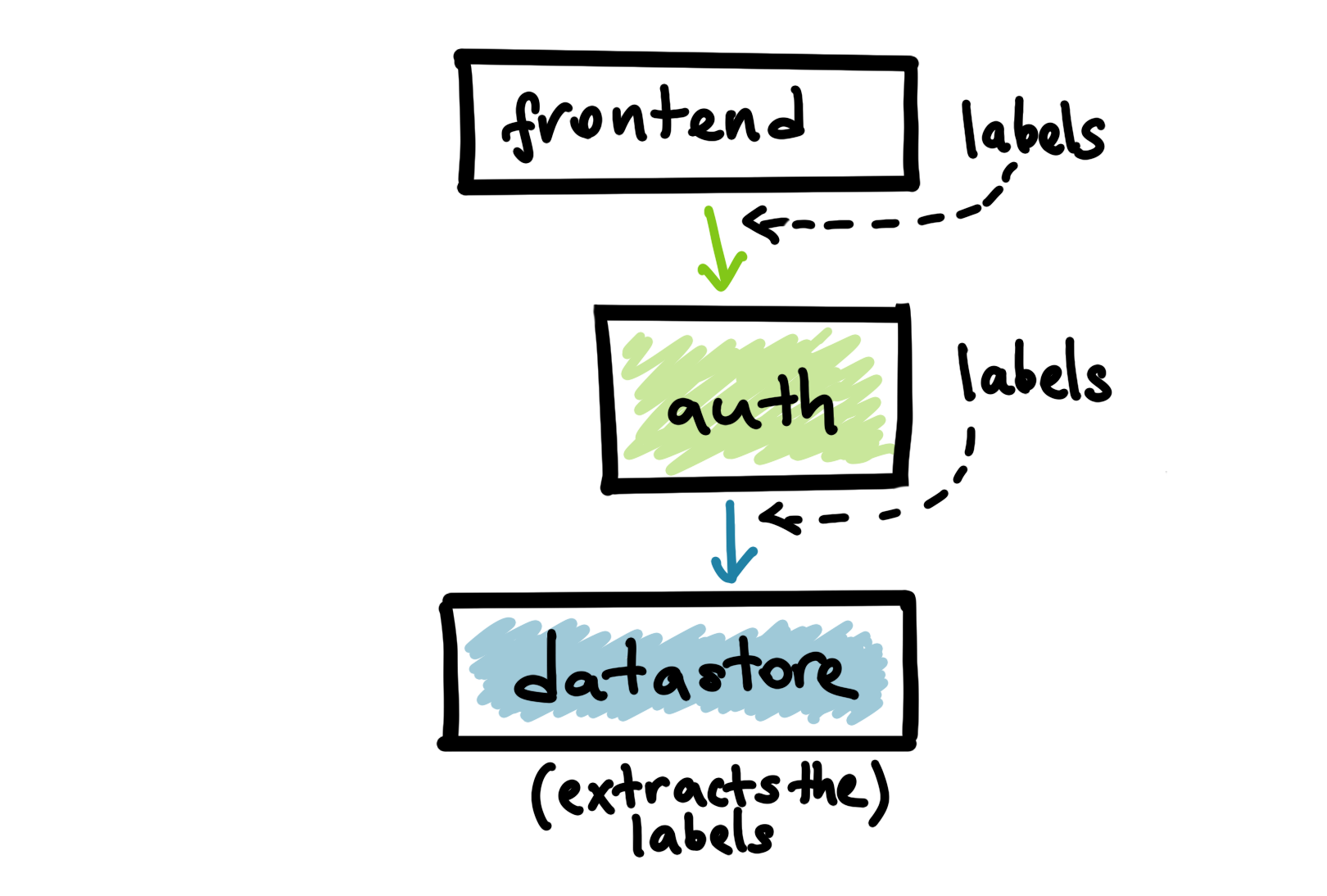
Context is the general concept to propagate various key/values among the services in distributed systems. We use the context to propagate the diagnostics related key/values in our systems. The receiving endpoint extracts the labels and keep propagating them if it needs to make more RPCs in order to respond to the incoming call.
Above high-level services such as the frontend and auth can produce or modify labels that will be used when datastore is recording metrics or logs. For example, datastore metrics can differentiate calls coming from a Web or a mobile client via labels provided at the frontend service.
This is how we have fine grained dimensions at the lower ends of the stack regardless of how many layers of services there are until a call is received at the lowest end.
We can then use observability signals to answer some of the critical questions such as:
- Is the datastore team meeting their SLOs for service X?
- What’s the impact of service X on the datastore service?
- How much do we need to scale up a service if service X grows 10%?
Propagating labels and collecting the diagnostics data are opening a lot of new ways to consume the observability signals in distributed systems. This is how your teams understand the impact of services all across the stack even if they don’t know much about the internals of each other’s services.