Persistent disks and replication
Note: This article mentions Google Cloud components.
If you are a cloud user, you probably have seen how unconventional storage options can get. This is even true for disks you access from your virtual machines. There are not many ongoing conversations or references about the underlying details of core infrastructure. One such lacking conversation is how fundamentally Google Persistent Disks and replication works.
Disks as services
Persistent disks are NOT local disks attached to the physical machines. Persistent disks are networking services and are attached to your VMs as network block devices. When you read or write from a persistent disk, data is transmitted over the network.
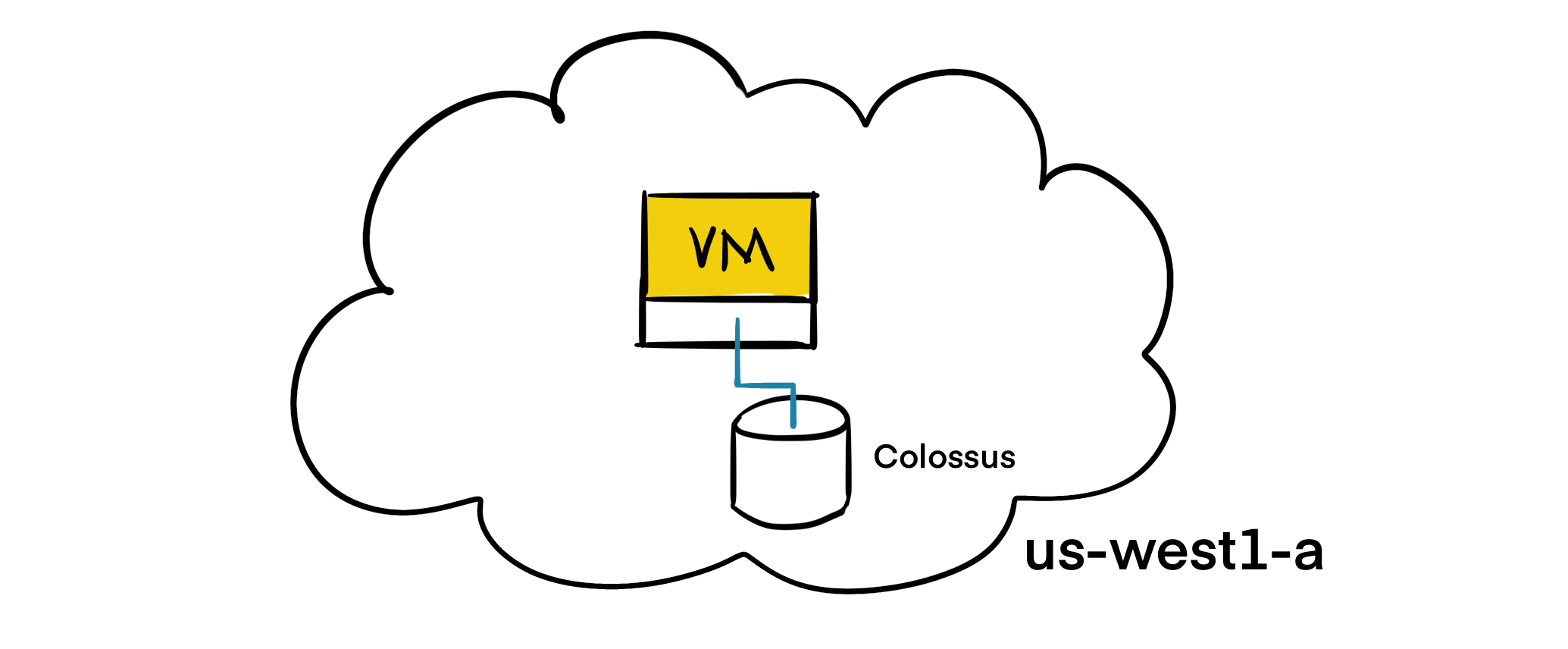
Persistent disks heavily rely on Google’s file system called Colossus. Colossus is a distributed block storage system that is serving most of the storage needs at Google. Persistent disk drivers automatically encrypt your data on the VM before it goes out of your VM and transmitted on the network. Then, Colossus persists the data. Upon a read, the driver decrypts the incoming data.
Having disks as a service is useful in various cases:
- Resizing the disks on-the-fly becomes easier. Without stopping a VM, you can increase the disk size (even abnormally).
- Attaching and detaching disks becomes trivial. Given disks and VMs don’t have to share the same lifecycle or to be co-located, it is possible to stop a VM and boot another one with its disk.
- High availability features like replication becomes easier. The disk driver can hide replication details and provide automatic write-time replication.
Disk latency
Users often wonder the latency overhead of having disks as a networking service. There are various benchmarking tools available. Below, there are a few reads of 4 KiB blocks from a persistent disk:
$ ioping -c 5 /dev/sda1
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=293.7 us (warmup)
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=330.0 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=278.1 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=307.7 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=310.1 us
--- /dev/sda1 (block device 10.00 GiB) ioping statistics ---
4 requests completed in 1.23 ms, 16 KiB read, 3.26 k iops, 12.7 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 278.1 us / 306.5 us / 330.0 us / 18.6 us
GCE also allows attaching local SSDs to virtual machines in cases where you have to avoid a longer roundtrip. If you are running a cache server or running large data processing jobs where there is an intermediate output, local SSDs would be your choice. Unlike persistent disks, data on local SSDs are NOT persistent and will be flushed each time your virtual machine restarts. It is only suitable for the optimization cases. Below, you can see the latency observed from 4 KiB reads from an NVMe SSD:
$ ioping -c 5 /dev/nvme0n1
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=245.3 us(warmup)
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=252.3 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=244.8 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=289.5 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=219.9 us
--- /dev/nvme0n1 (block device 375 GiB) ioping statistics ---
4 requests completed in 1.01 ms, 16 KiB read, 3.97 k iops, 15.5 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 219.9 us / 251.6 us / 289.5 us / 25.0 us
Replication
When creating a new disk, you can optionally choose to replicate the disk within region. Persistent disks are replicated for higher availability. Replication happens within a region between two zones.
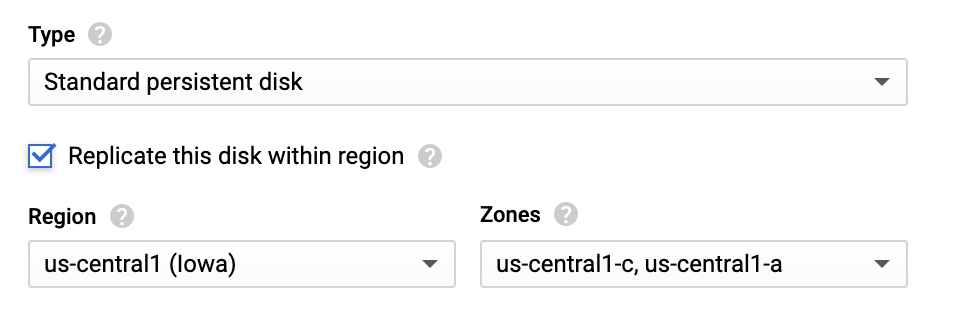
It is unlikely for a region to fail altogether but zonal failures happen more commonly. Replicating within the region at different zones is a good bet from the availability and disk latency perspective. If both replication zones fail, it is considered a region-wide failure.
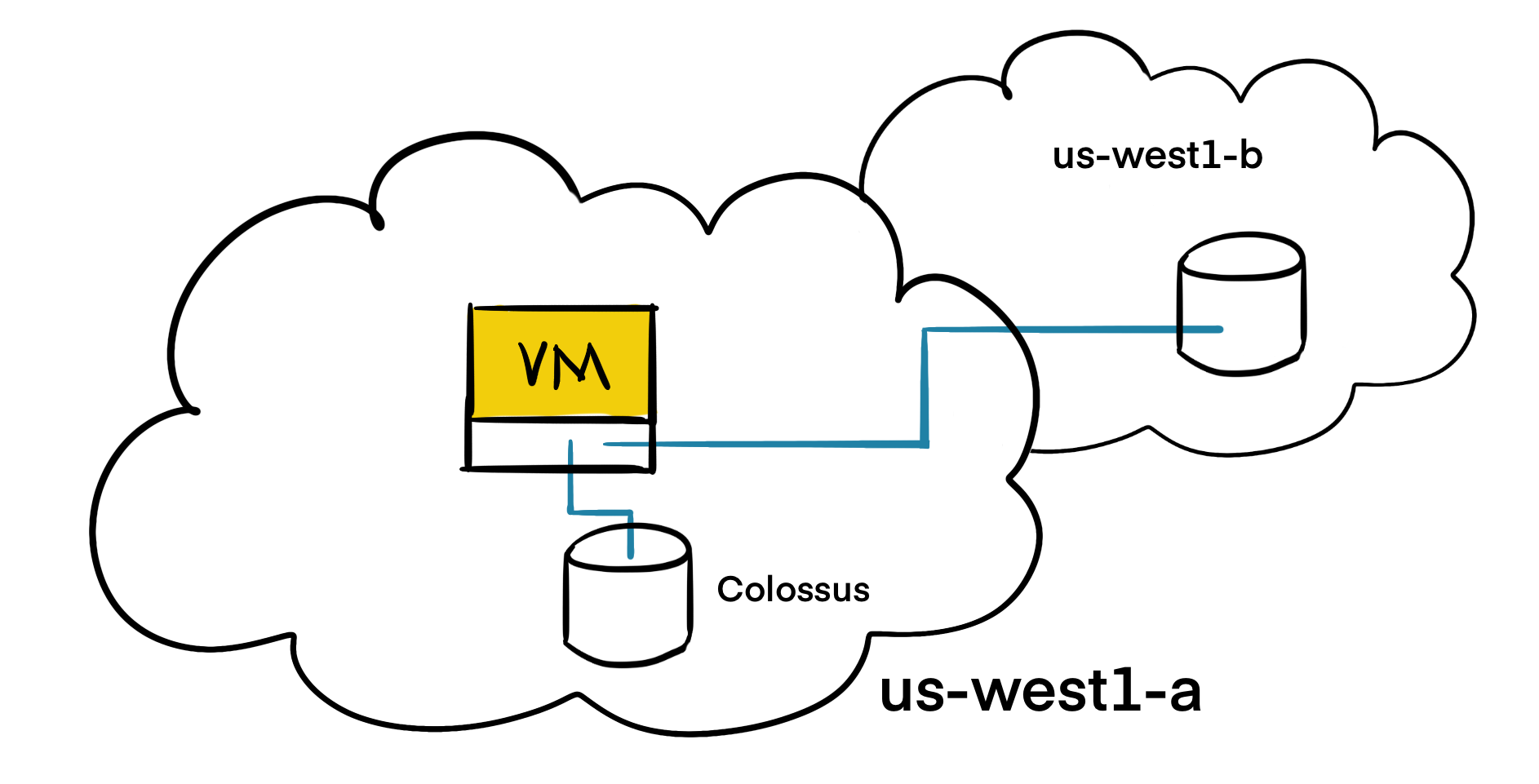
In the replicated scenario, the data is available in the local zone (us-west1-a) which is the zone the virtual machine is running in. Then, the data is replicated to another Colossus instance in another zone (us-west1-b). At least one of the zones should be the same zone the VM is running in. Please note that, persistent disk replication is only for the high availability of the disks. Zonal outages may also affect the virtual machines or other components that might cause outage.
Read/write sequences
The heavy work is done by the disk driver in the user VM. As a user, you don’t have to deal with the replication semantics, and can interact with the file system the usual way. The underlying driver handles a sequence for reading and writing.
When a replica falls behind and replication is incomplete, read/writes go through the trusted replica until a reconciliation happens. Otherwise, we are in the full replication mode.
In the full replication mode:
- When writing, a write request tries to write to both replicas and acknowledge when both writes succeed.
- When reading, read request is sent to the local replica at the zone the virtual machine is running in. If the read request times out, another read request is sent to the remote replica.
It is not always obvious to the users that persistent disks are network storage devices. They enable many use cases and functionality in terms of capacity, flexibility and reliability conventional disks cannot provide.