NUMA
Non-uniform memory access (NUMA) is an approach to optimize memory access time in multi-processor architectures. In NUMA architectures, processors can access to the memory chips near them instead of going to the physically distant ones.
In the distant past CPUs generally ran slower than the memory. Today, CPUs are quite faster than the memory they use. This became a problem because processors constantly started to wait for data to be retrieved from the memory. As a result of such data starvation problems, for example, CPU caches became a popular addition to modern computer architecture.
With multi processors architectures, the data starvation problem became worse. Only one processor can access the memory at a time. With multiple processors trying to access to the same memory chip resulted in further wait times for the processors.
NUMA is an architectural design and a set of capabilities trying to address problems such as:
- Data-intensive situations where processors are starving for data.
- Multi-processor architectures where processors non-optimally race for memory access.
- Architectures with large number of processors where physical distance to memory is a problem.
Nodes
NUMA architectures consist of an array of processors closely located to a memory. Processors can also access the remote memory but the access is slower.
In NUMA, processors are grouped together with local memory. These groups are called NUMA nodes. Almost all modern processors also contains a non-shared memory structure, CPU caches. Access to the caches are the fastest, but shared memory is required if data needs to be shared. In shared cases, access to the local memory is the fastest. Processors also have access to remote memory. The difference is that accessing remote memory is slower because the interconnect is slower.
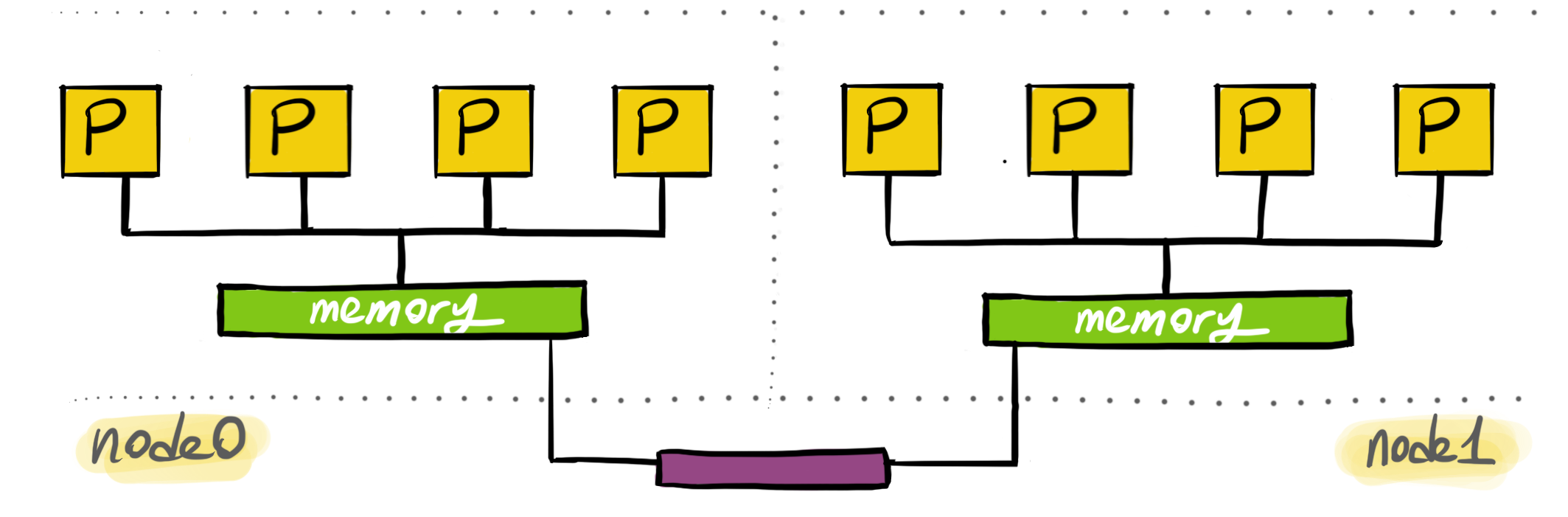
NUMA architectures provide APIs for the users to set fine-tuned affinities. The main way how this works is to allocate memory for a thread on its local node. Then, make the thread running in the same node. This will allow the optimal data access latency for memory.
Linux users might be familiar with sched_setaffinity(2) which allows its users to
lock a thread on a specific processor. Think about NUMA APIs as a way to
lock a thread to a specific set of processors and memory. Even if the thread is preempted,
it will only start rerunning on a specific node where data locality is optimal.
NUMA in Linux
Linux has NUMA support for a while. NUMA supports provides tools, syscalls and libraries.
numactl allows to set affinities and gather information about
your existing system. To gather information about the NUMA nodes,
run:
$ numactl --hardware
You can set affinities of a process you are launching. The following will set the CPU node affinity of the launching process to node 0 and will only allocate from 0.
$ numactl --cpubind=0 --membind=0 <cmd>
You can allocate memory preferable on the given node. It will still allocate memory in other nodes if memory can't be allocated on the preferred node:
$ numactl --preferred=0 <cmd>
You can launch a new process to allocate always from the local memory:
$ numactl --localalloc <cmd>
You can selectively only execute on the given CPUs. In the following case, the new process will be executed either on processor 0, 1, 2, 5 or 6:
$ numactl --physcpubind=0-2,5-6 <cmd>
See numactl(8) for the full list of capabilities. Linux kernel supports NUMA architectures by providing some syscalls. From user programs, you can also call the syscalls. Alternatively, numa library provides an API for the same capabilities.
Optimizations
Your programs may need NUMA:
- If it's clear from the nature of the problem that memory/processor affinity is needed.
- If you have been analyzing CPU migration patterns and locking a thread to a node can improve the performance.
Some of the following tools could be useful diagnosing the need for optimizations.
numastat(8) displays some
hits or misses per node. You can see if memory is allocated as intended on the
prefered nodes. You can also see how often memory is allocated on local vs remote.
numatop allows you to inspect the local vs remote memory access stats of the running processes.
You can see the distance between nodes via numactl --hardware to avoid allocating from distant nodes.
This will allow you to optimize to avoid the overhead of the interconnect.
If you need to further analyze thread scheduling and migration patterns, tracing tools such as Schedviz might be useful to visualize kernel scheduling decisions.
One more thing…
Recently, on the Go Time podcast, I briefly mentioned how I'm directly calling into libnuma from Go programs for NUMA affinity. I think, everyone was thinking I was joking. In Go, runtime scheduler doesn't allow you to have precise control or doesn't expose the underlying processor/architecture. If you are running highly CPU intensive goroutines with strict memory access requirements, NUMA bindings might be an option.
One thing you need to make sure is to lock the OS thread, so the goroutine is kept being scheduled to run on the same OS thread which can set its affinity via NUMA APIs.
DON'T TRY THIS HOME (unless you know what you are doing):
import "github.com/rakyll/go-numa"
func main() {
if !numa.IsAvailable() {
log.Fatalln("NUMA is not available on this machine.")
}
// Make sure the underlying OS thread
// doesn't change because NUMA can only
// lock the OS thread to a specific node.
runtime.LockOSThread()
// Runs the current goroutine always in node 0.
numa.SetPreferred(0)
// Allocates from the node's local memory.
numa.SetLocalAlloc()
// Do work in this goroutine...
}
Please don't use this if you are 100% sure what you are doing. Otherwise, it will limit the Go scheduler and your programs will see a significant performance penalty.